
Fakelab – A Deepfake Audio Detection Tool

Introduction
In September 2019 Reynold Journalism Institute , Columbia Missouri opened a deepfake verification Competition. RJI Student Innovation Competition challenge is to create a program, tool or prototype for photo, video or audio verification.

RJI 3rd Place Winner :
On February 8 Our team FakeLab Won the 3rd place at RJI Student Innovation Competition.

What is DeepFakes
Deepfakes are images, videos or voices that have been manipulated through the use of sophisticated machine-learning algorithms to make it almost impossible to differentiate between what is real and what isn’t.
Popular techniques for creating audio deepfakes.
Speech Synthesis:
- Speech synthesis is the artificial production of human speech.
- Computer or instrument used is speech synthesizer.
- Text-To-Speech (TTS) synthesis is production of speech from normal language text.
Voice Conversion:
Transform the speech of a (source) speaker so that it sound- like the speech of a different (target) speaker.
FakeLab
We at University of Missouri Kansas City came up with solution to detect deepfakes called FakeLab.
Fakelab is a tool for journalists, media houses and tech companies that helps in identifying manipulated photos, videos and audio shared on their platforms.

Below are detailed steps of our work for DeepFake Audio
Working
To discern between real and fake audio, the detector uses visual representations of audio clips called spectrograms, which are also used to train speech synthesis models.
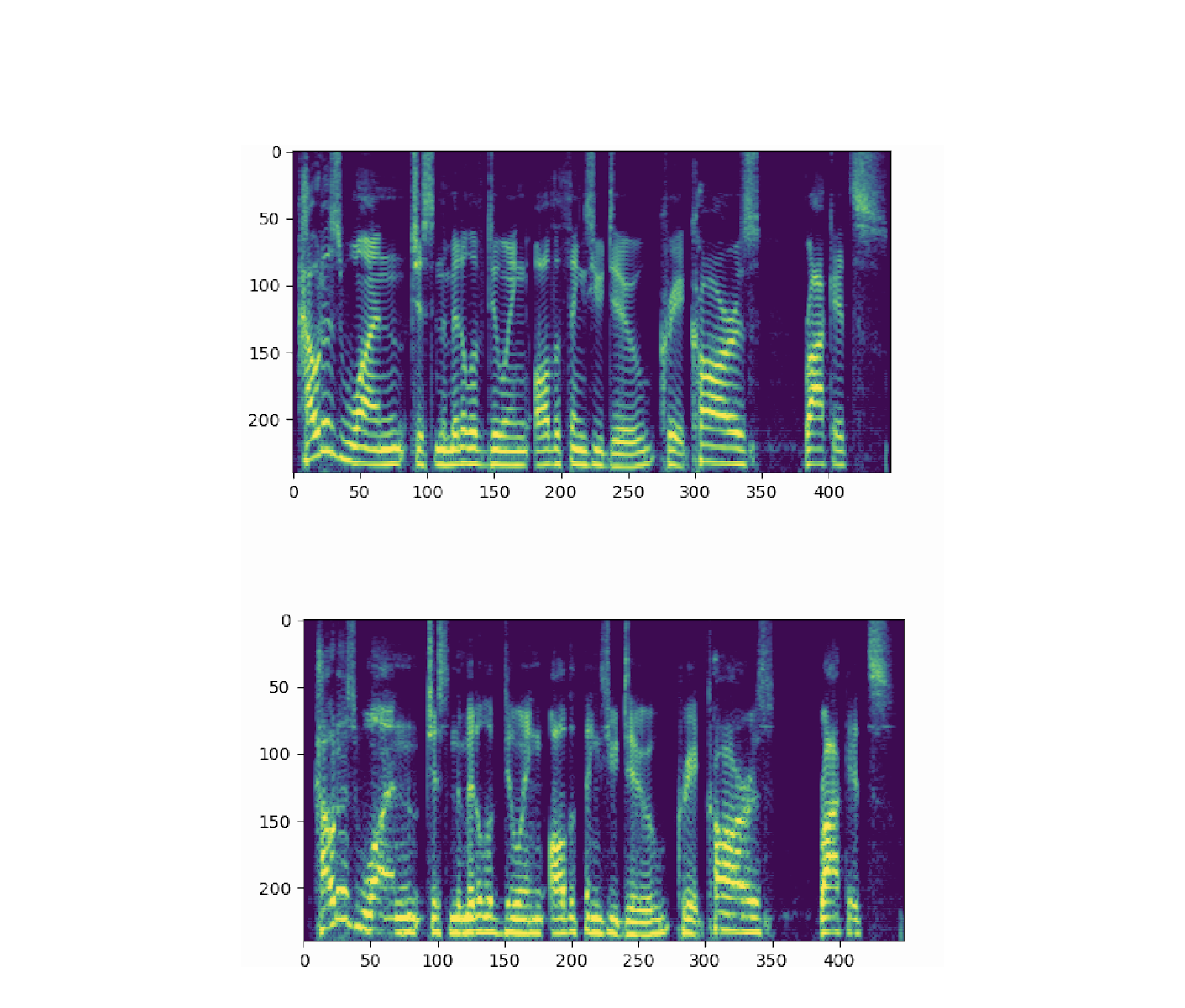
While to the unsuspecting ear they sound basically identical, spectrograms of real audio vs. fake audio actually *look* different from one another.
The data
We trained the detector on Google’s 2019 AVSSpoof dataset, released earlier this year by the company to encourage the development of audio deepfake detection. The dataset contains over 25,000 clips of audio, featuring both real and fake clips of a variety of male and female speakers.
The model
The deepfake detector model is a deep neural network that uses Temporal convolution. Here’s a high-level overview of the model’s architecture:
First, raw audio is preprocessed and converted into a mel-frequency spectrogram — this is the input for the model. The model performs convolutions over the time dimension of the spectrogram, then uses masked pooling to prevent overfitting. Finally, the output is passed into a dense layer and a sigmoid activation function, which ultimately outputs a predicted probability between 0 (fake) and 1 (real).
Results
Dessa’s baseline model achieved 99%, 95%, and 85% accuracy on the train, validation, and test sets respectively. The differing performance is caused by differences between the three datasets. While all three datasets feature distinct and different speakers, the test set uses a different set of fake audio generating algorithms that were not present in the train or validation set.
Put more simply, our detector model can currently predict over 90% of the fake audio clips it is shown.
FakeLab UI
In order to get the inference for test video we have created the Web UI for keeping the record of all inference run on test files.
Here is Demo

Github
All the source code we used in model training is available at GitHub here
I like your blog. Its one of the great blogs online
Thank you!